Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Int4 Precision for AI Inference | NVIDIA Technical Blog
KV Cache INT8 and INT4 quantization precision reduction · Issue #772 ...
Why INT4 is presented as performance of GPUs? - Deep Learning - fast.ai ...
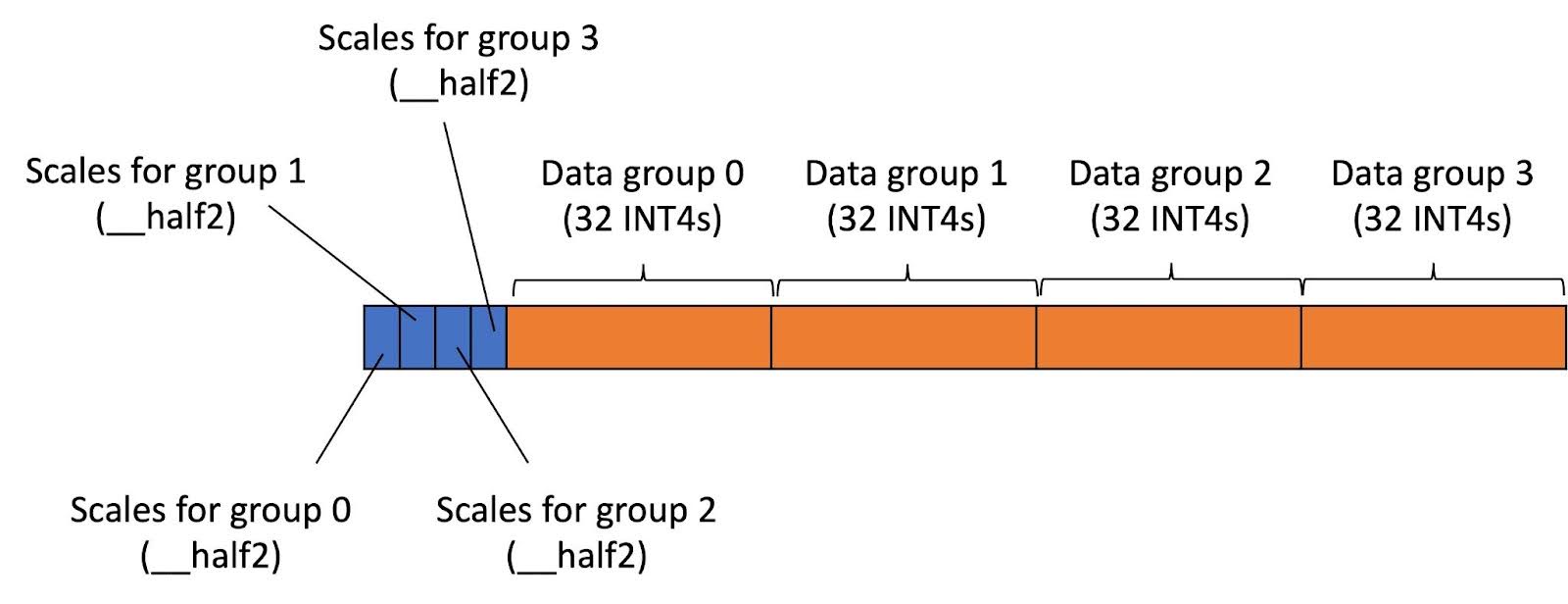
INT4 Quantization: Group-wise Methods & NF4 Format for LLMs ...
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
INT4
Understanding Int4 scalar quantization in Lucene - Search Labs
🔢 INT4 vs FP4: The Future of 4-Bit Quantization
INT4 and other low-precision conversion support status · Issue #64193 ...
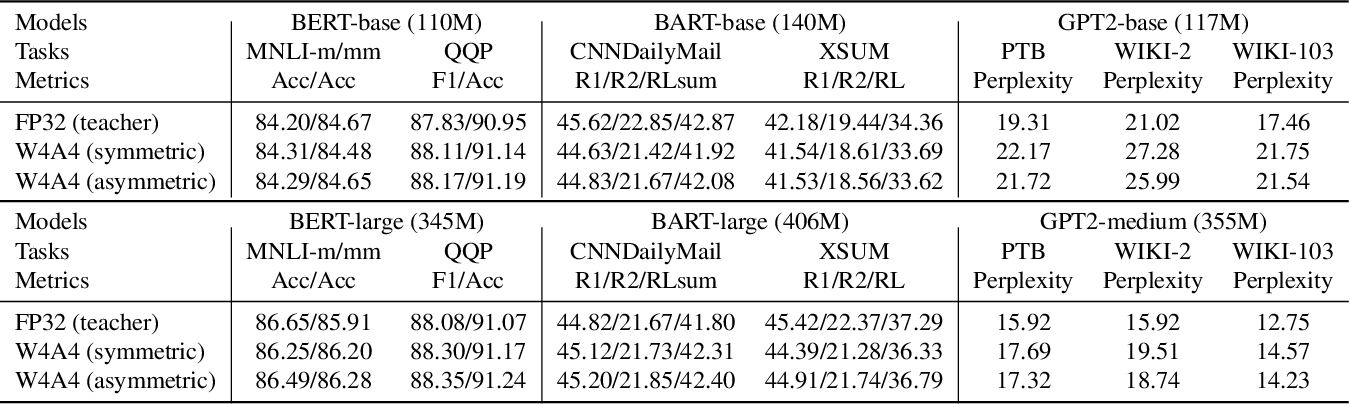
[2301.12017] Understanding INT4 Quantization for Language Models ...
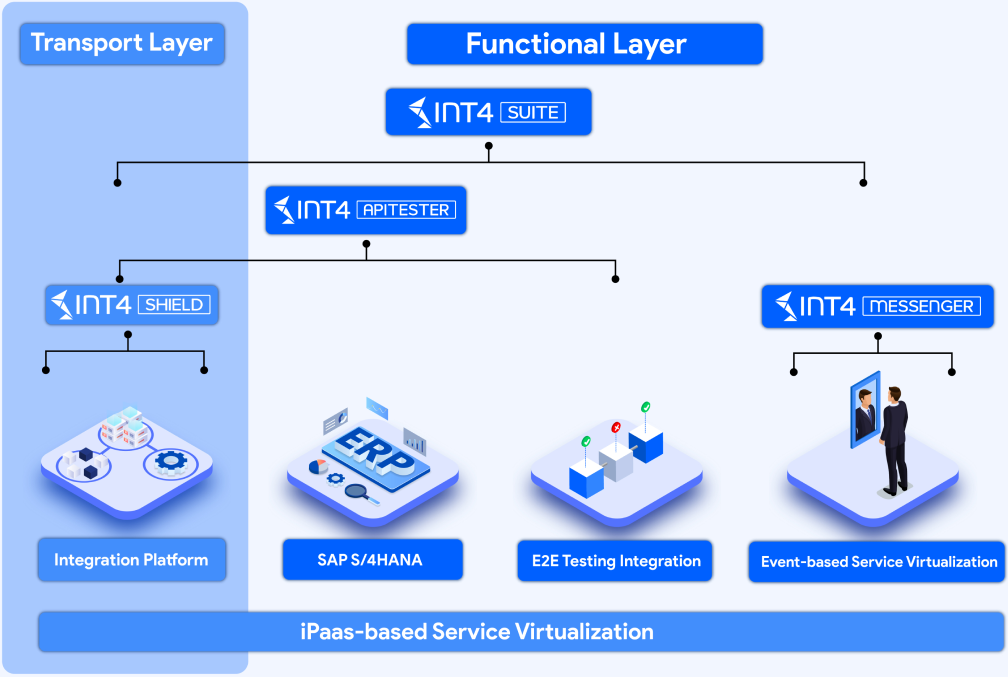
Int4 Suite Help Portal
[Quantization] int4 vs fp4 which to choose?
Int4 - Tech Details
INT4 Quantization (with code demonstration)
Unlocking Model Quantization: Why Precision Matters in Deep Learning ...
Understanding Int4 scalar quantization in Lucene — Search Labs ...
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
hugging-quants/Meta-Llama-3.1-70B-Instruct-AWQ-INT4 · How to use INT4 ...
zai-org/glm-4v-9b · How to run the Int4 quantized model?
[RFC][Tensorcore] INT4 end-to-end inference - pre-RFC - Apache TVM Discuss
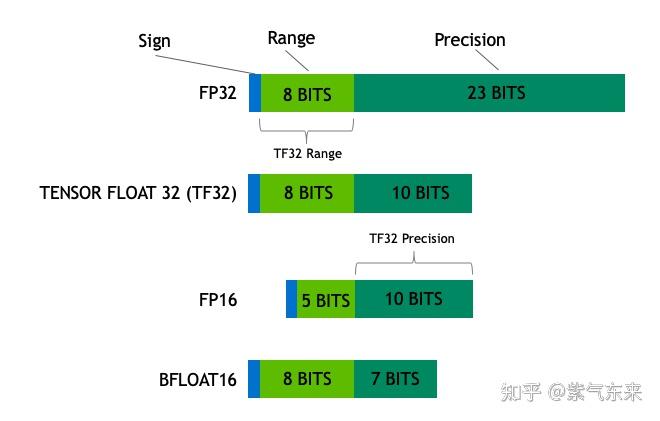
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
INT4 vs NF4: Optimizing Model Weights for Efficiency | khuram shahzad ...
int4 Weight Quantization - LLM Compressor Docs
How LLMs run faster with INT4 quantization | Borys Nadykto posted on ...
Suite – INT4
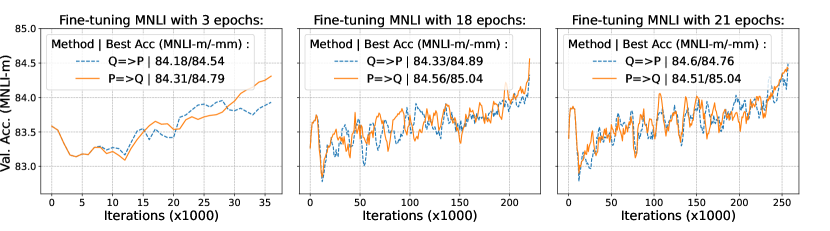
Table 1 from Understanding Int4 Quantization for Language Models ...
int4 vs int8 vs uuid vs numeric performance on bigger joins
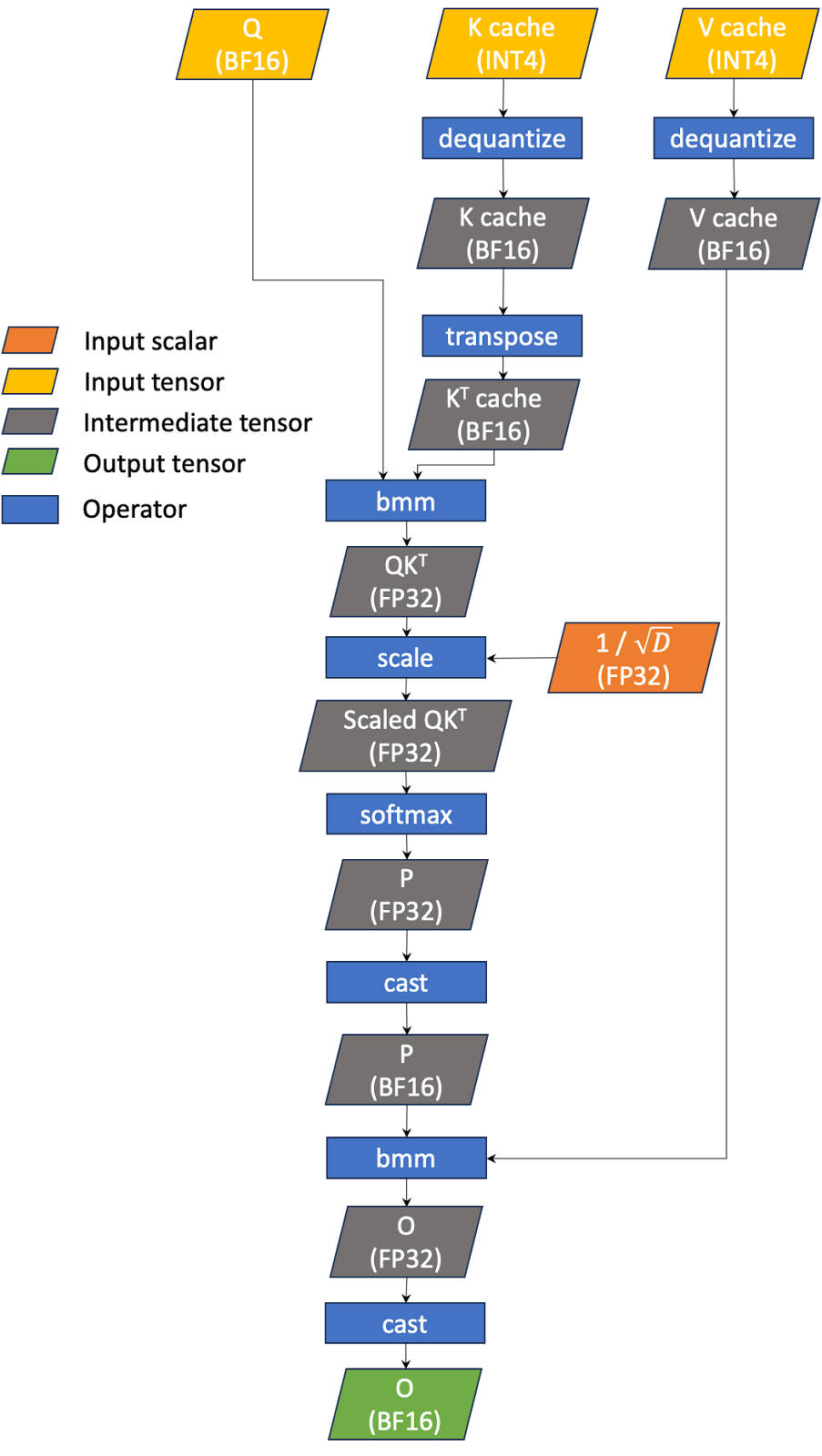
INT4 Decoding GQA CUDA Optimizations for LLM Inference | PyTorch
INT4 - SAPinsider
About – INT4
Why do ENTERPRISE CUSTOMERS use Int4 Suite? | Most important BENEFITS ...
Model for llama-3-8B, EP: cpu, precision: int4 generated using ...
Praca IT w Int4
Questions about int4 quantization · Issue #60125 · tensorflow ...
Figure 3 from Understanding INT4 Quantization for Transformer Models ...
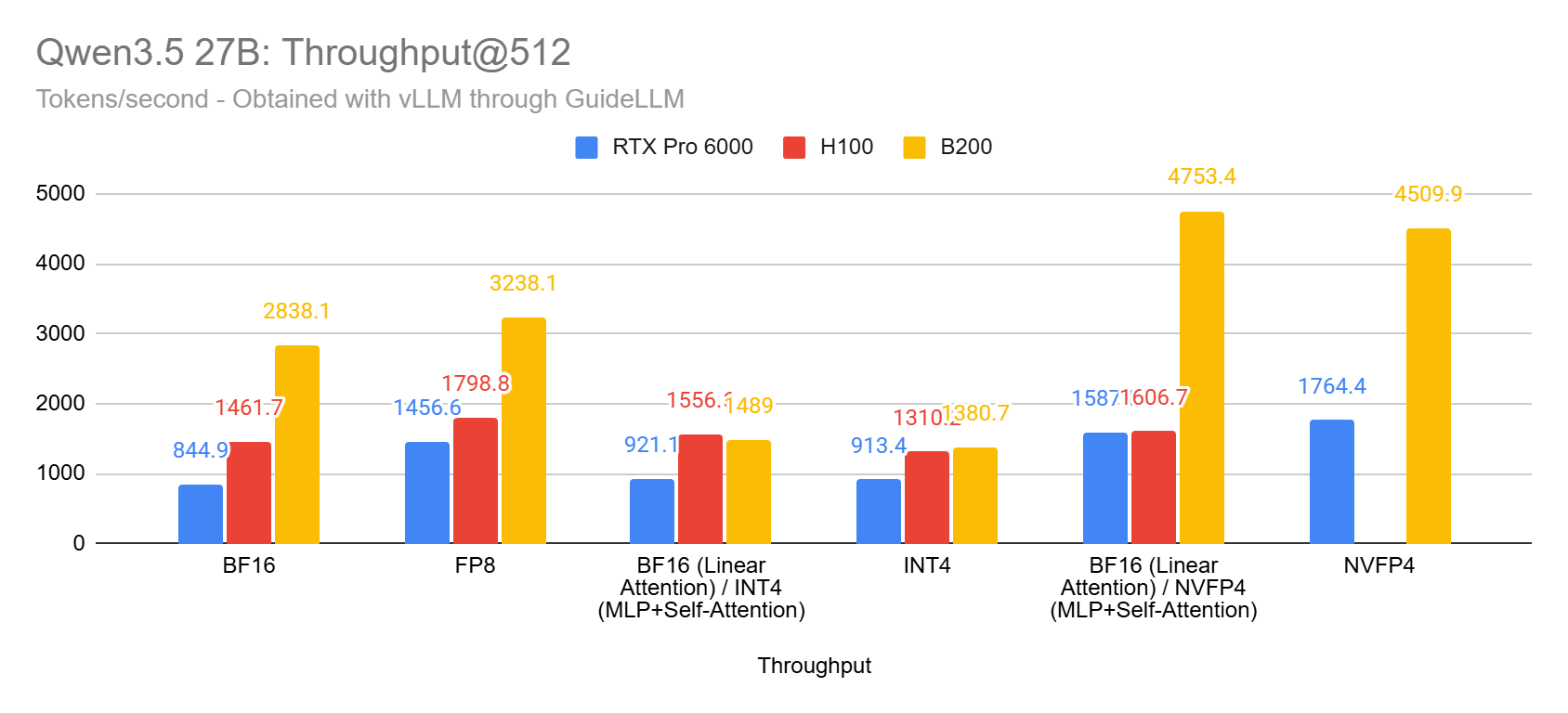
Qwen3.5 27B Latency and Throughput: INT4 vs NVFP4 vs FP8 vs BF16
Int4 Suite Knowledge Center Library
INT4 Decoding GQA CUDA Optimizations for LLM Inference – PyTorch
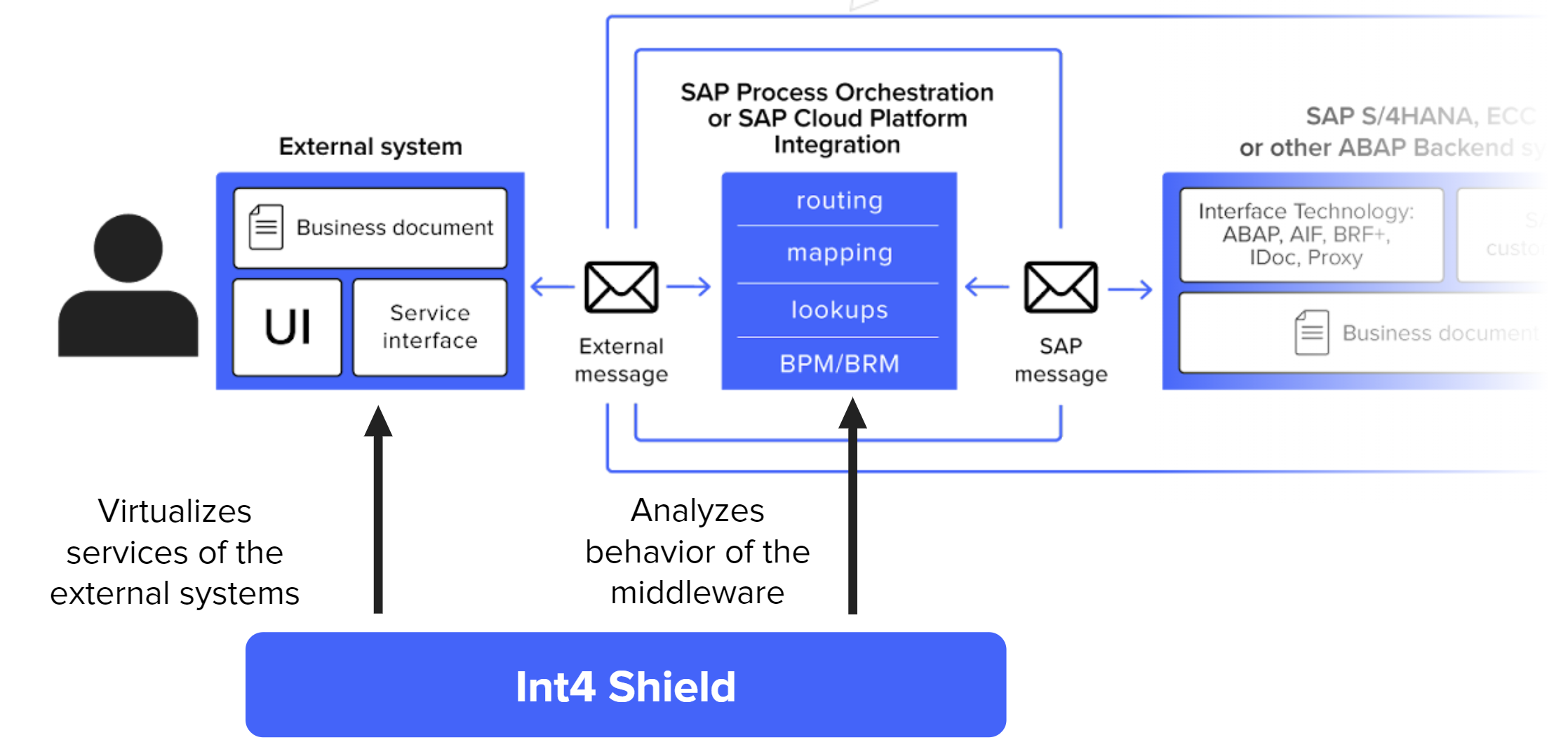
Int4 Shield
[Feature] Can you please do INT4 Quantization for InternVL2-26B and ...
Excited to have completed the Int4 Suite training! | Anirudh S
INT4 load cell digital panel meter calibration - EASY! - YouTube
Day 62/75 Why INT1 INT4 not used in LLM Quantization | What are ...
Quark Quantized INT4 Models - a amd Collection
#sap | Int4
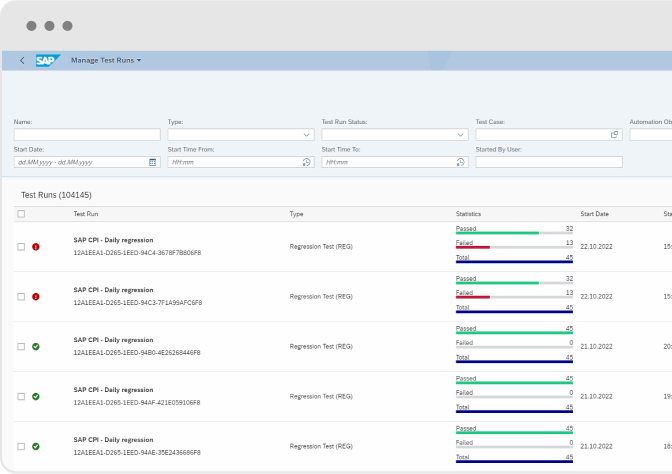
What is Int4 Shield? Testing in SAP Integration Platform Migration ...
How Int4 Suite can improve master data integrity | Int4 posted on the ...
How Int4 Suite simplifies SAP Transformation | Int4 posted on the topic ...
Int4 Suite is used by numerous Fortune 500 Companies and Global Giants ...
Careers – INT4
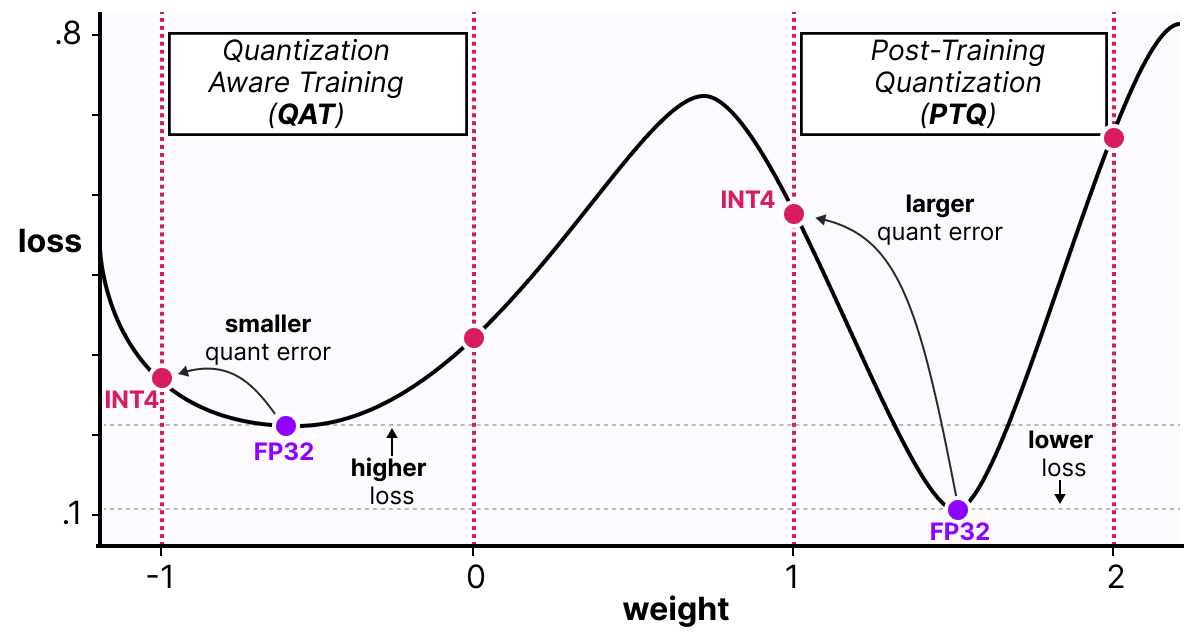
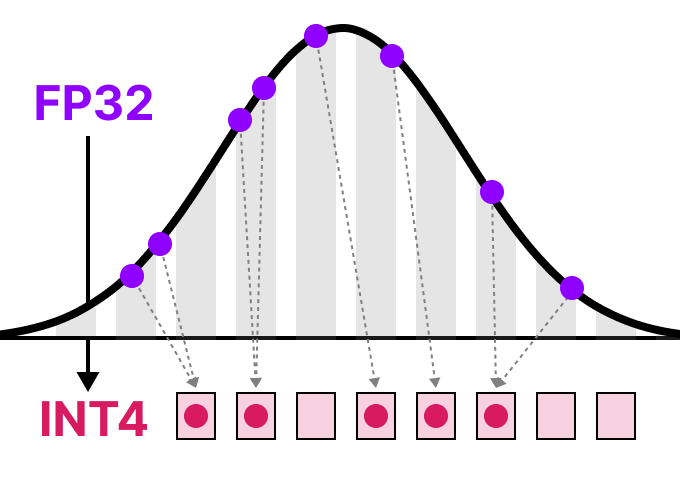
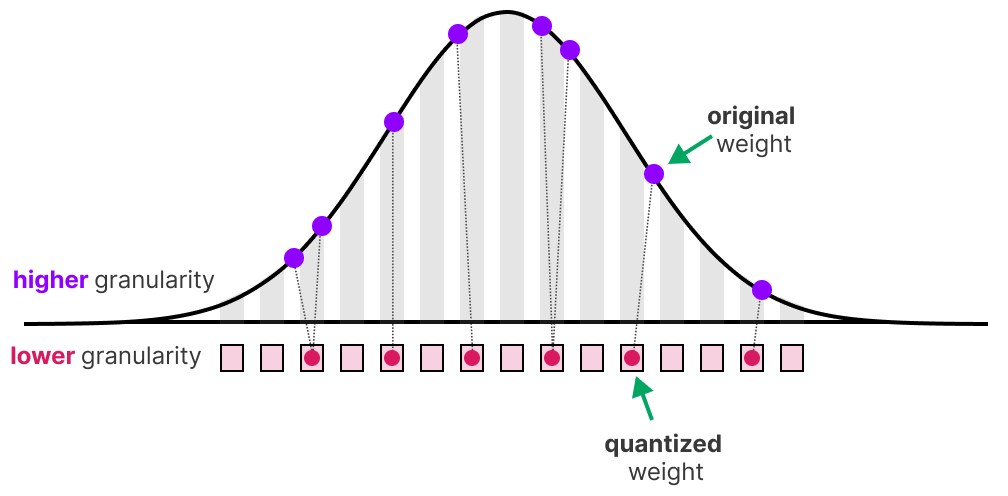
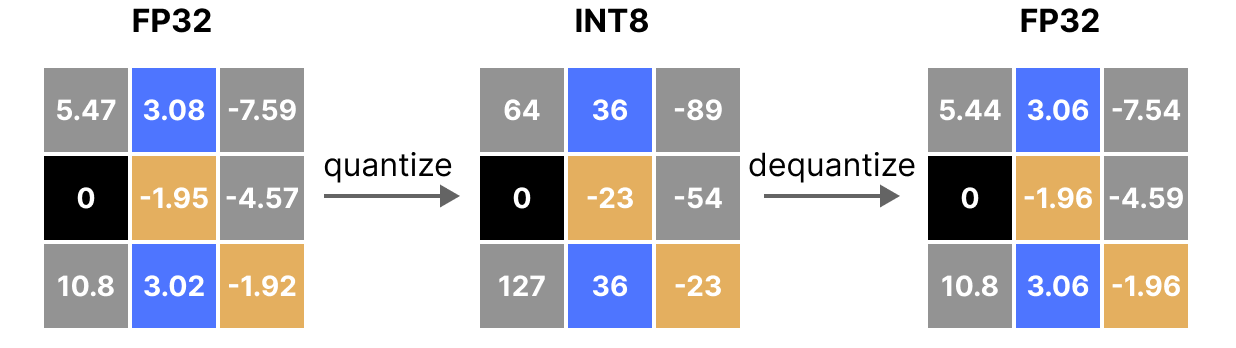
A Visual Guide to Quantization - by Maarten Grootendorst
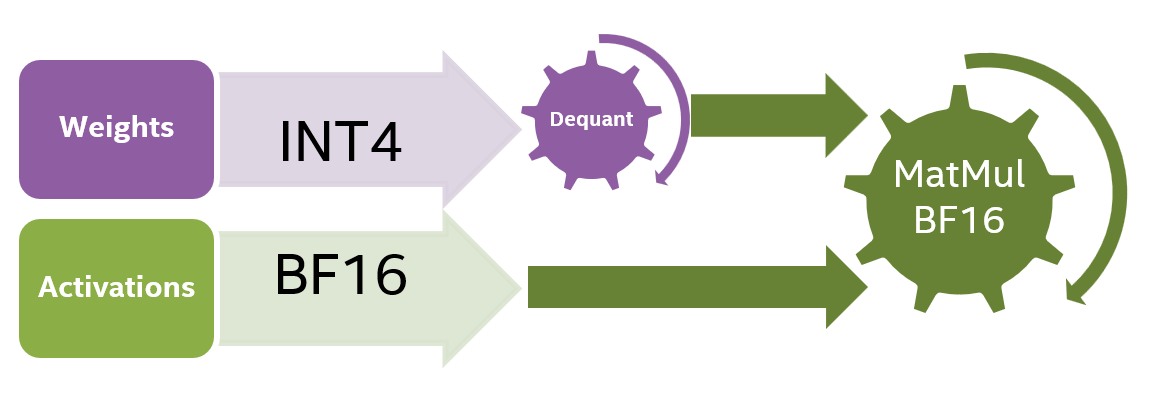
4-bit LLM training and Primer on Precision, data types & Quantization
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
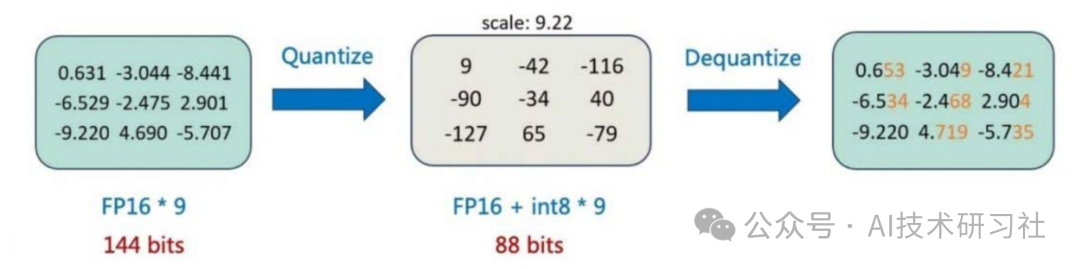
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
A Visual Guide to Quantization - Maarten Grootendorst
top-1 accuracy of fp32, Tensorflow's INT4-8 and AB INT4- 4 ...
Extremely Low Bit Transformer Quantization for On-Device NMT | PDF
AutoRound Meets SGLang: Enabling Quantized Model Inference with ...
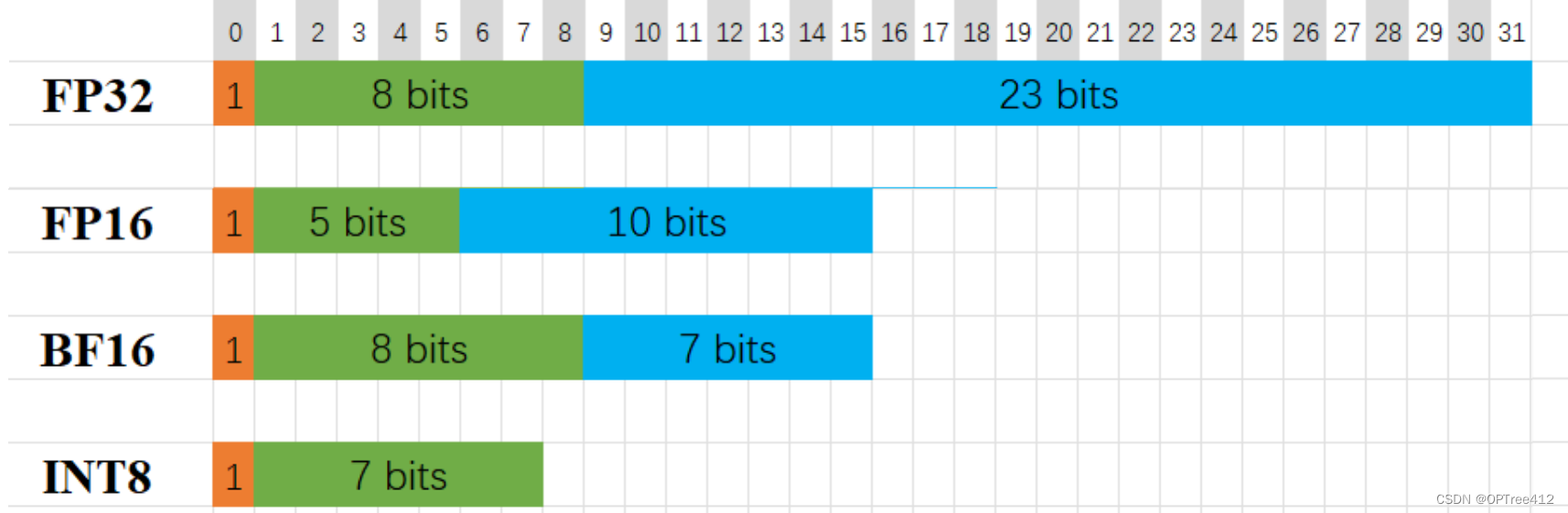
Model Memory Requirements Explained: How FP32, FP16, BF16, INT8, and ...
FP16 to INT4: 4x Throughput Boost with Minimal Accuracy Loss | Deepak ...
pe-nlp/deepseek-pt-v3-quantized-int4 at main
大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析_顺其自然~-MCP技术社区
Lunar Lake’s iGPU: Debut of Intel’s Xe2 Architecture
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度_风闻
Cuantización de modelos LLM: INT4/INT8 sin perder precisión
Deploying Kimi K2 Thinking at 173 Tokens per Second: How Simplismart ...
tiiuae/Falcon3-1B-Instruct-GPTQ-Int4 · Hugging Face
Accelerating Generative AI with PyTorch II: GPT, Fast | PyTorch
转载:【AI系统】完全分片数据并行 FSDP - 日照金城 - 博客园
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
大模型量化部署进阶:从 INT8/INT4 原理到高性能推理实战 - 知乎
使用 珞 Optimum Intel 在英特尔至强上加速 StarCoder: Q8/Q4 及投机解码 - HuggingFace - 博客园
How Glencore uses Data-Driven Intelligence for Intercompany ...
INT4-L - Novatech
Intel/Qwen3-VL-30B-A3B-Instruct-int4-AutoRound · Hugging Face
mit-han-lab/svdq-int4-flux.1-depth-dev · Hugging Face
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 墨天轮
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???_混合精度训练和fp32的区别-CSDN博客
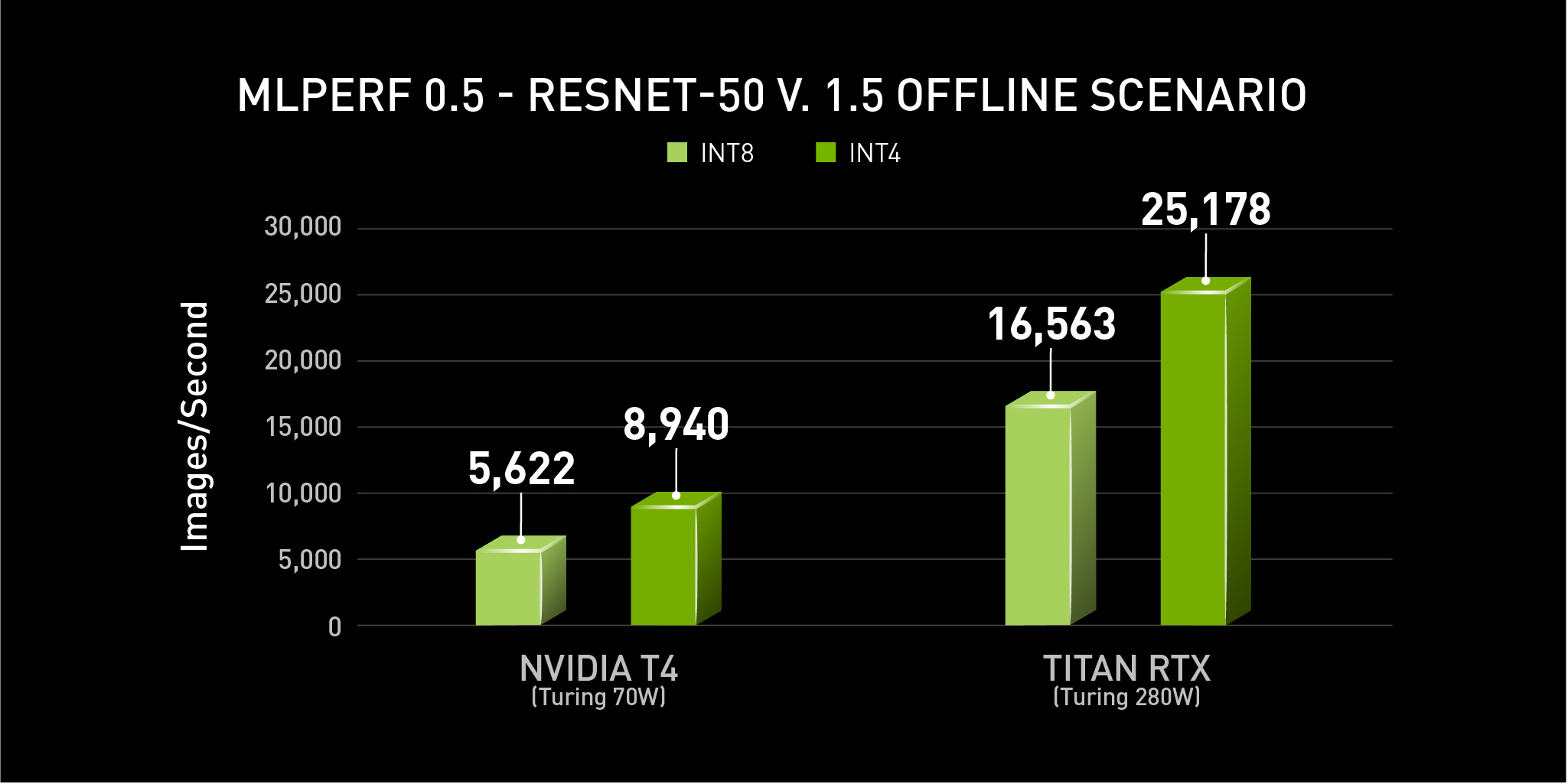
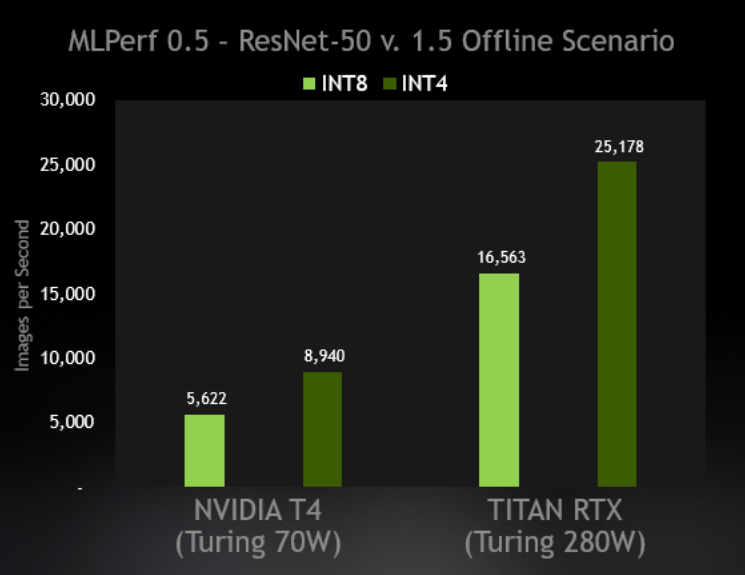

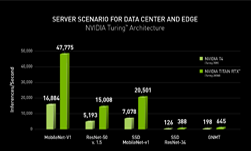
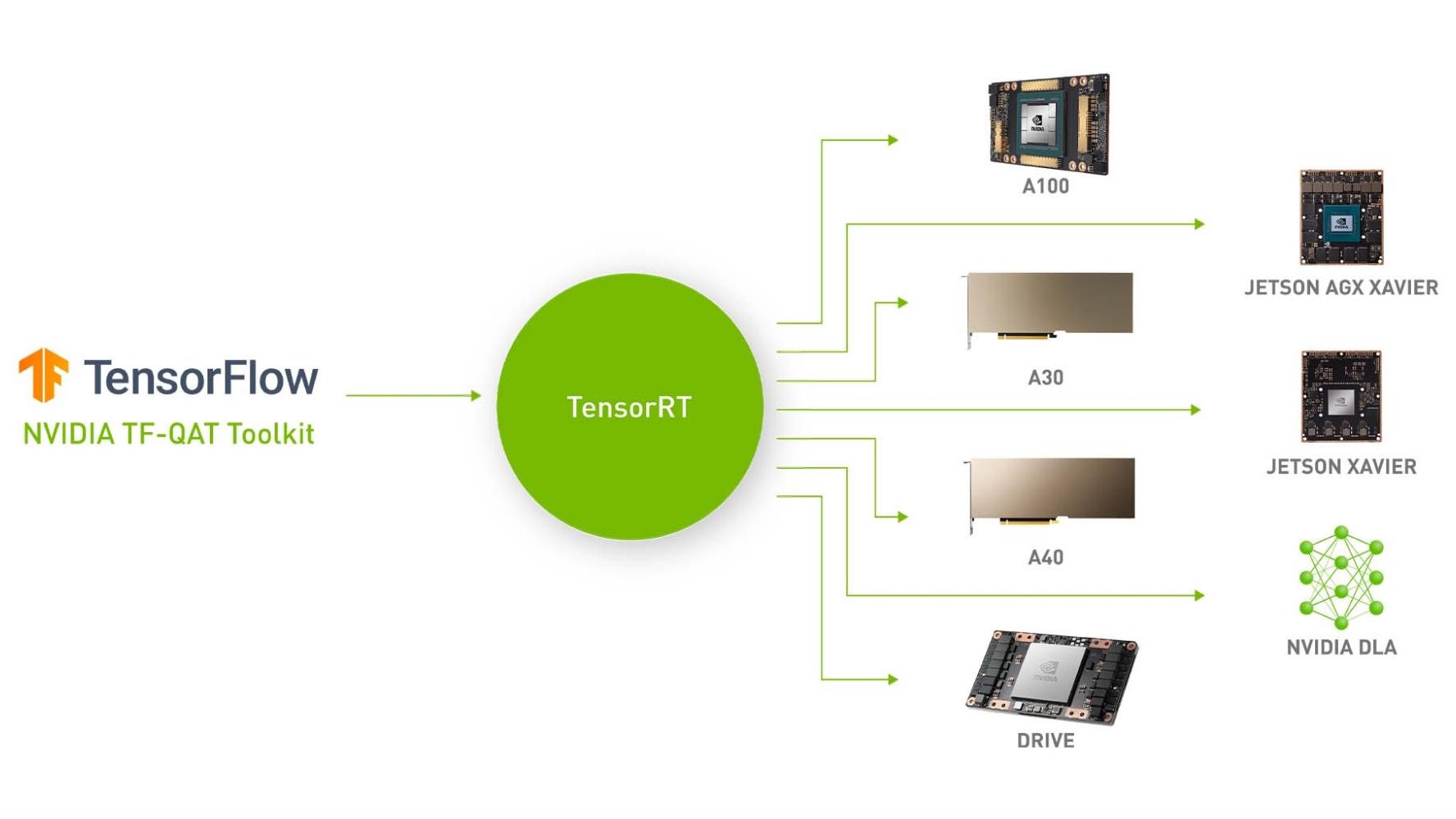























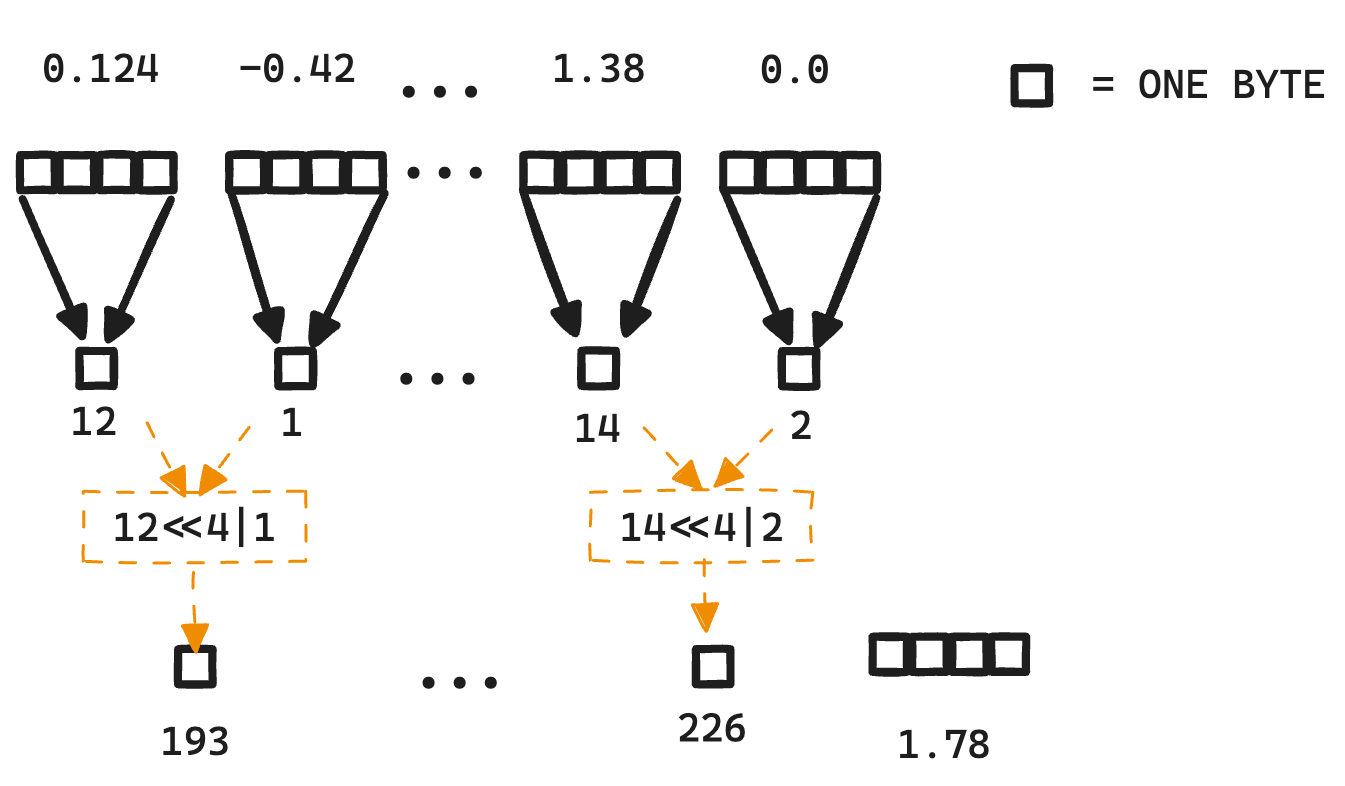

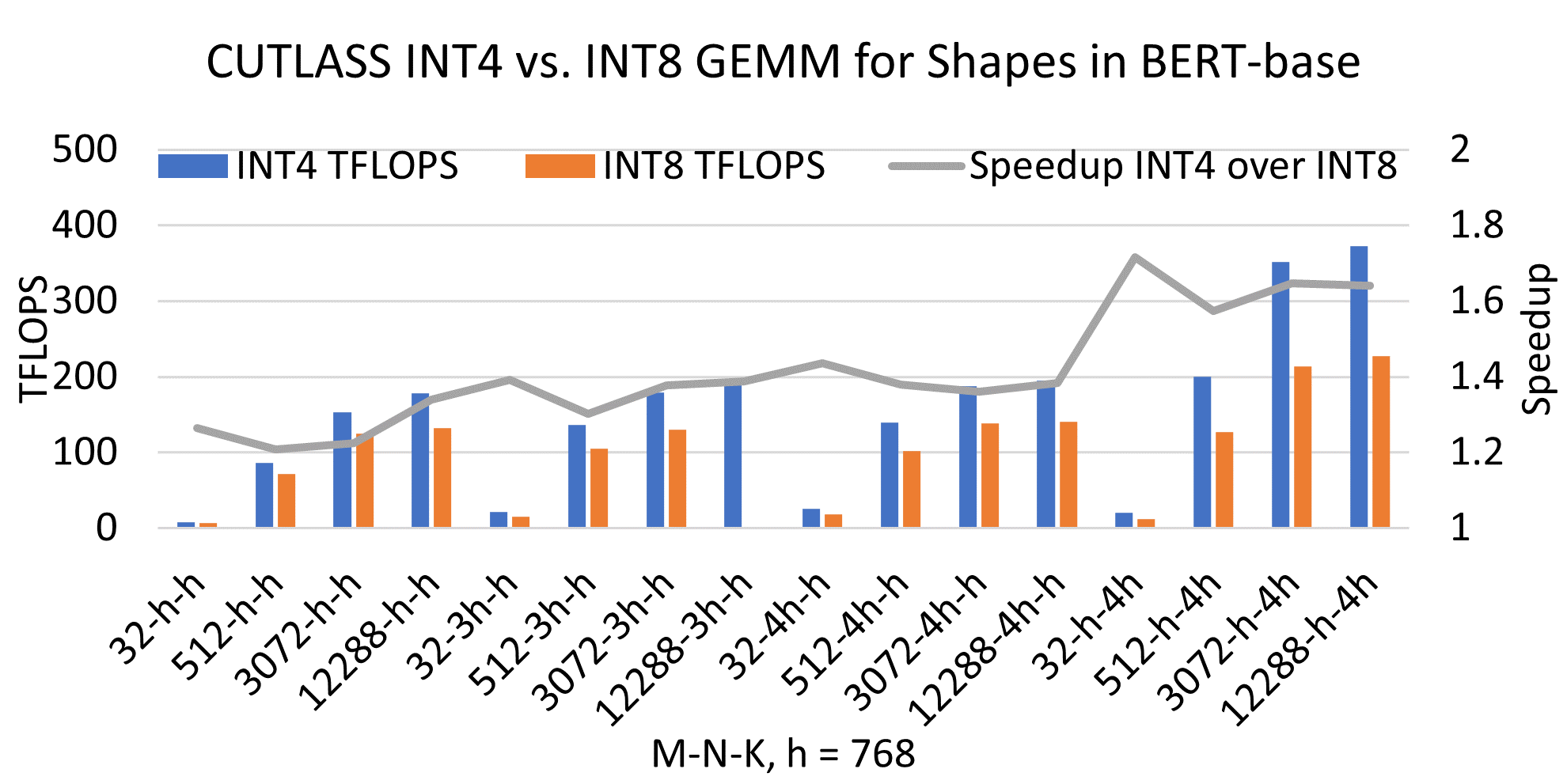
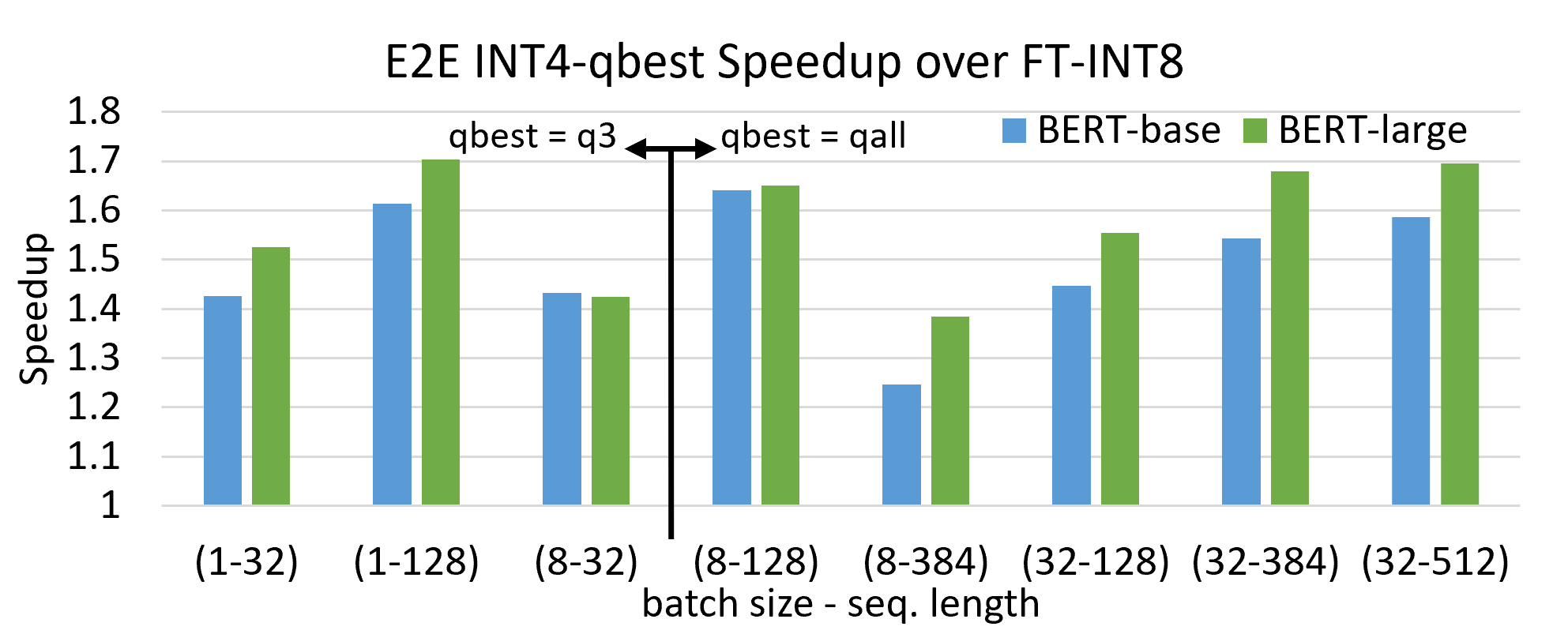










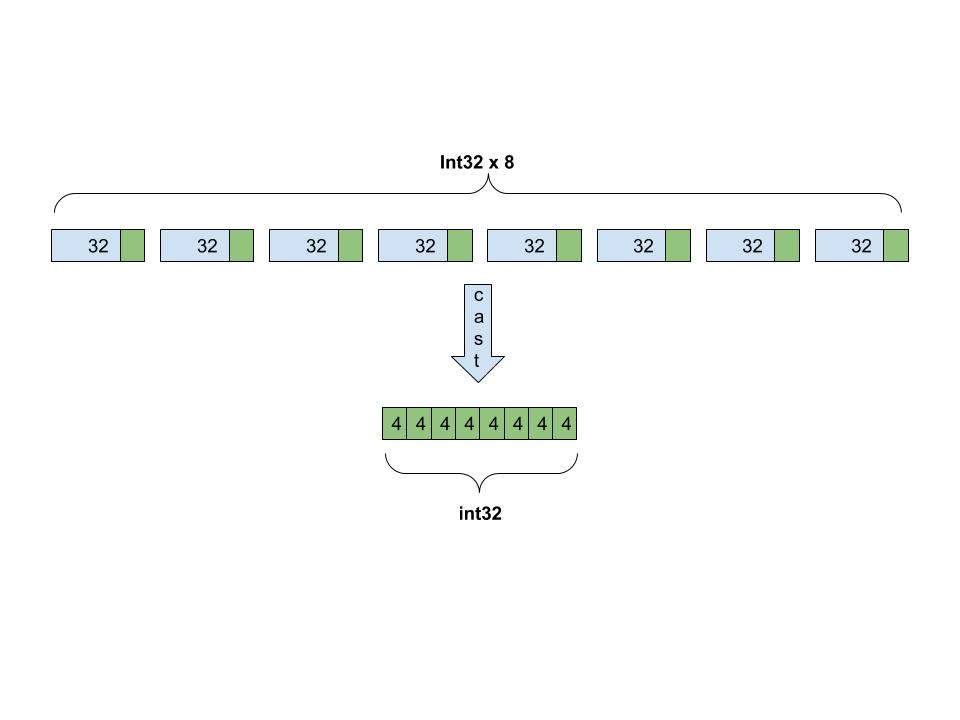






















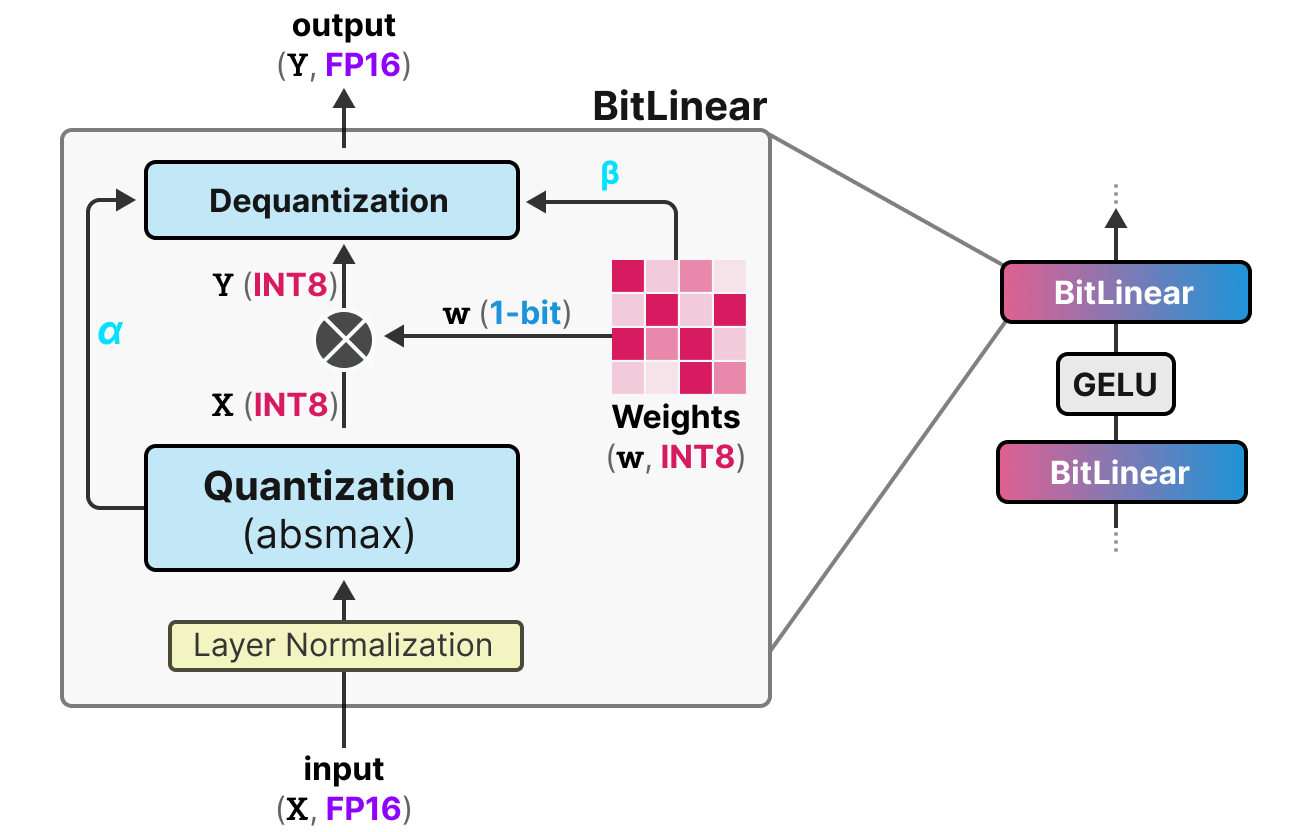


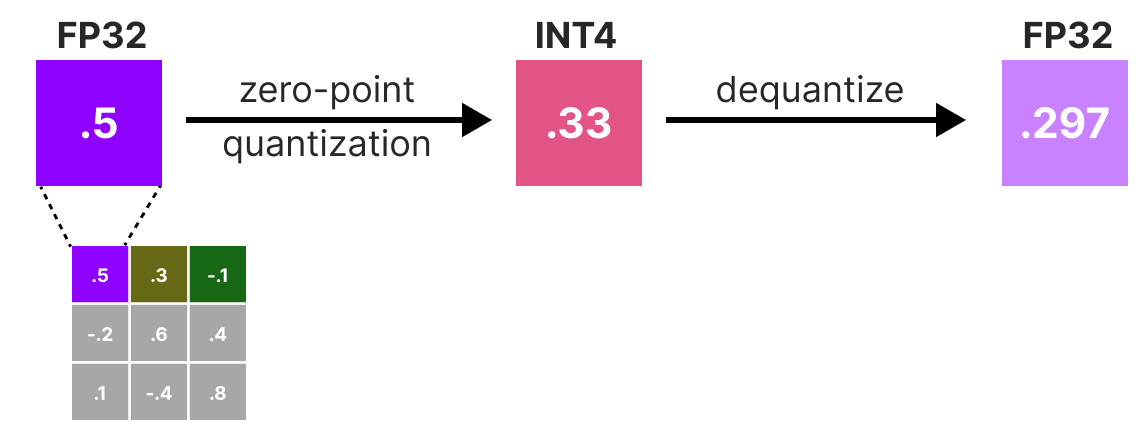



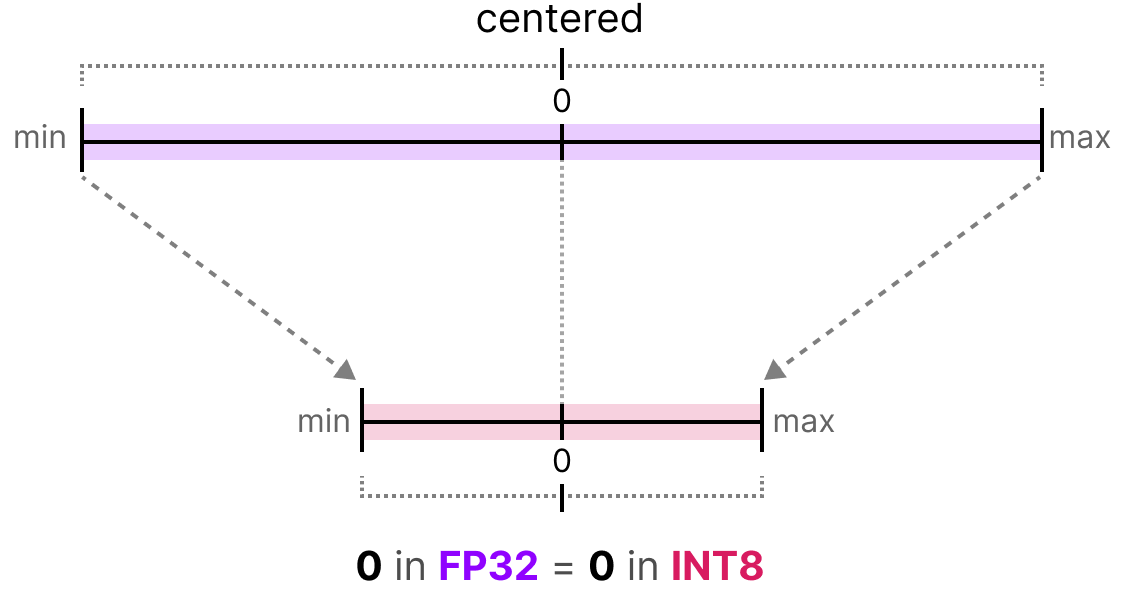




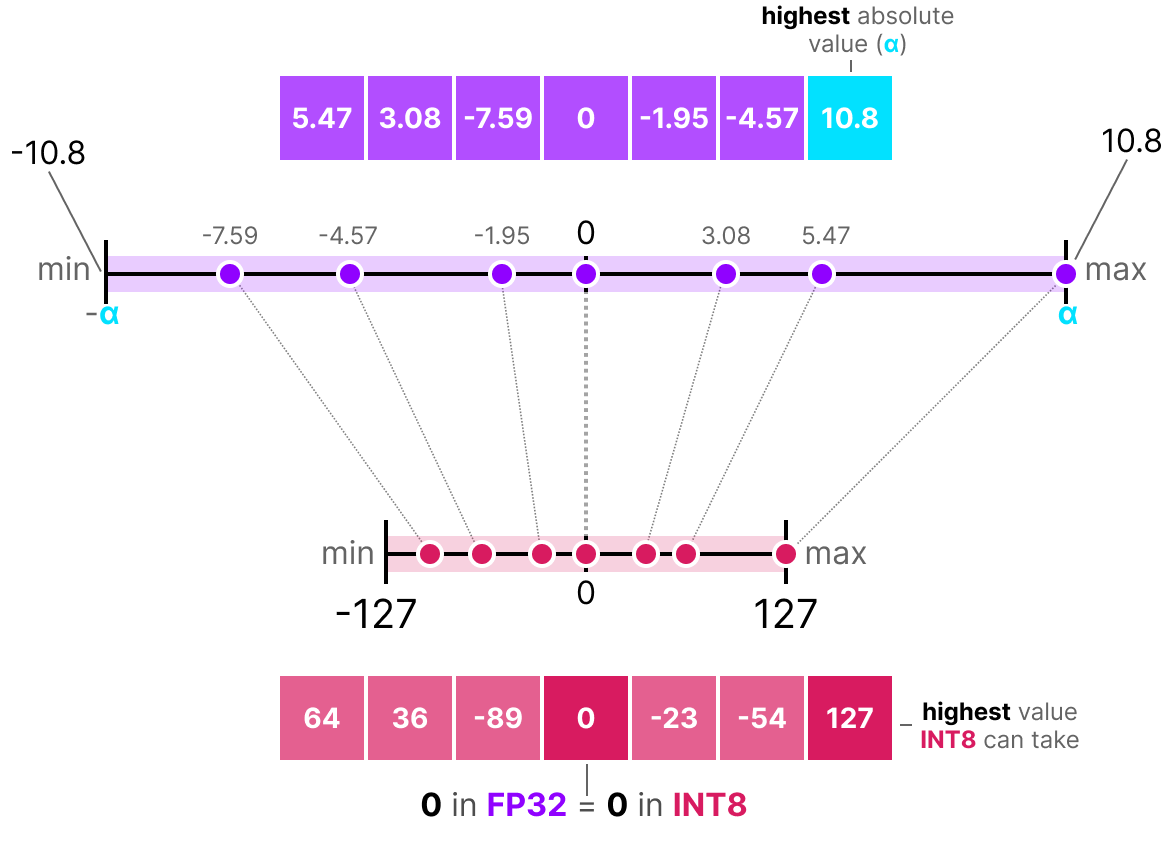

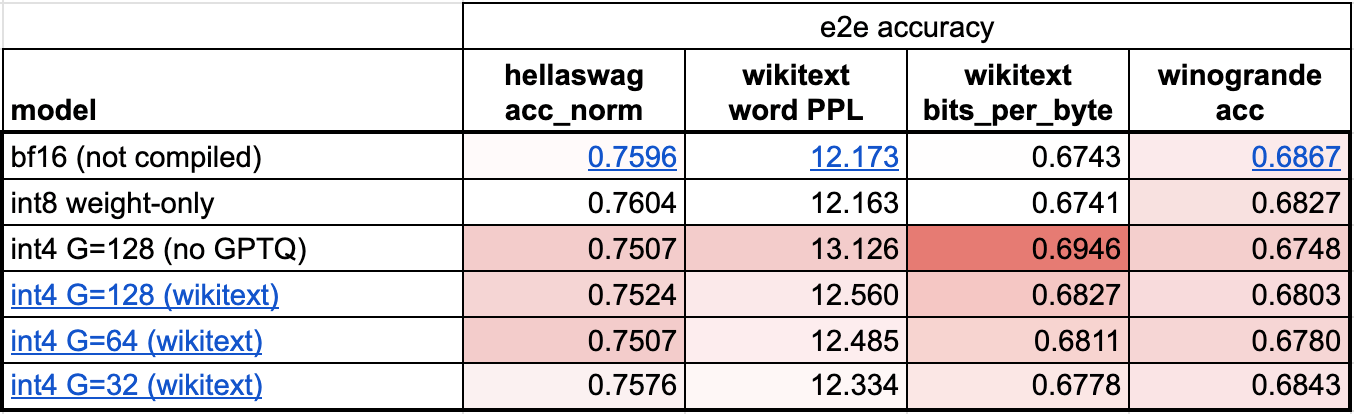

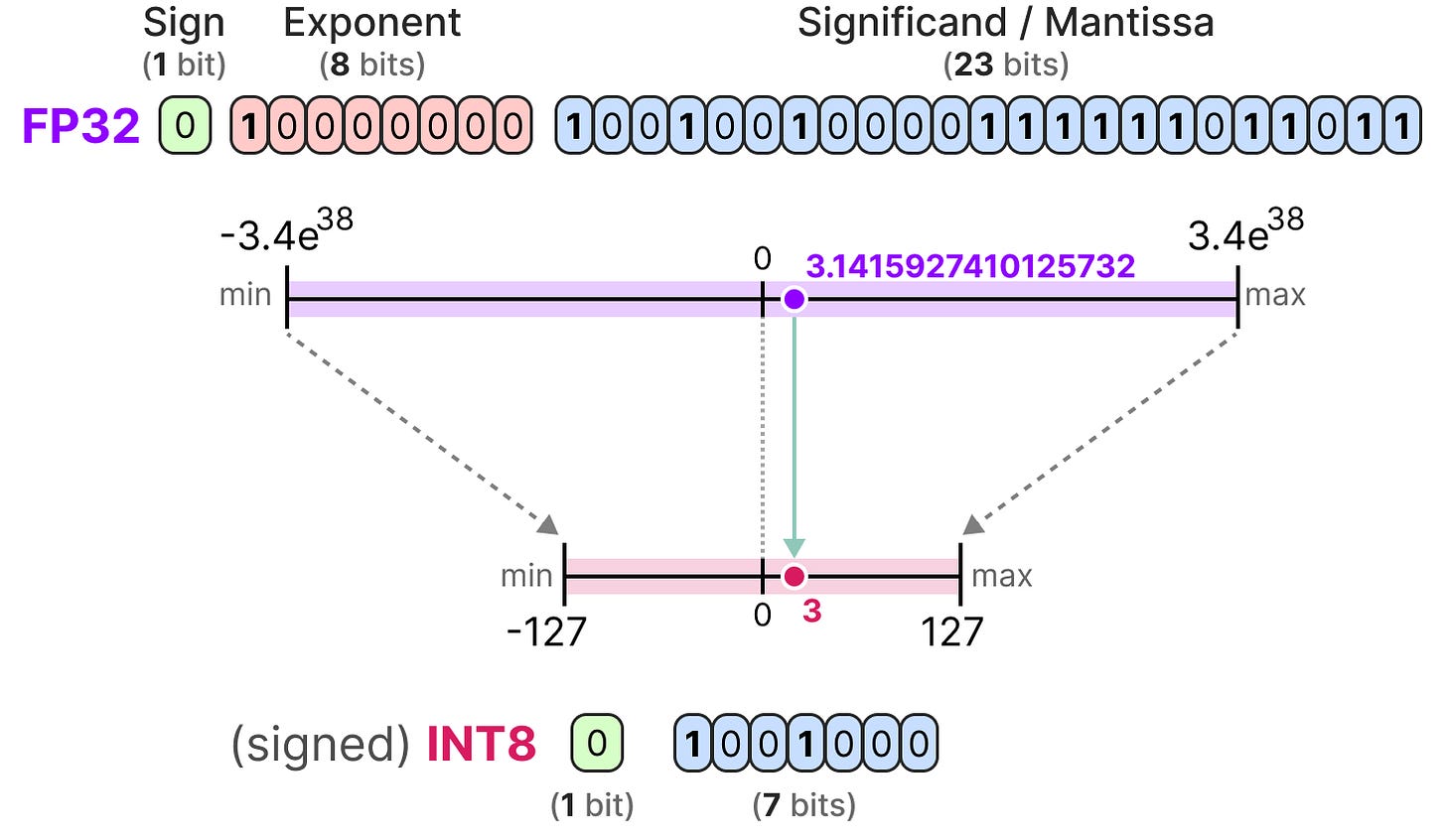


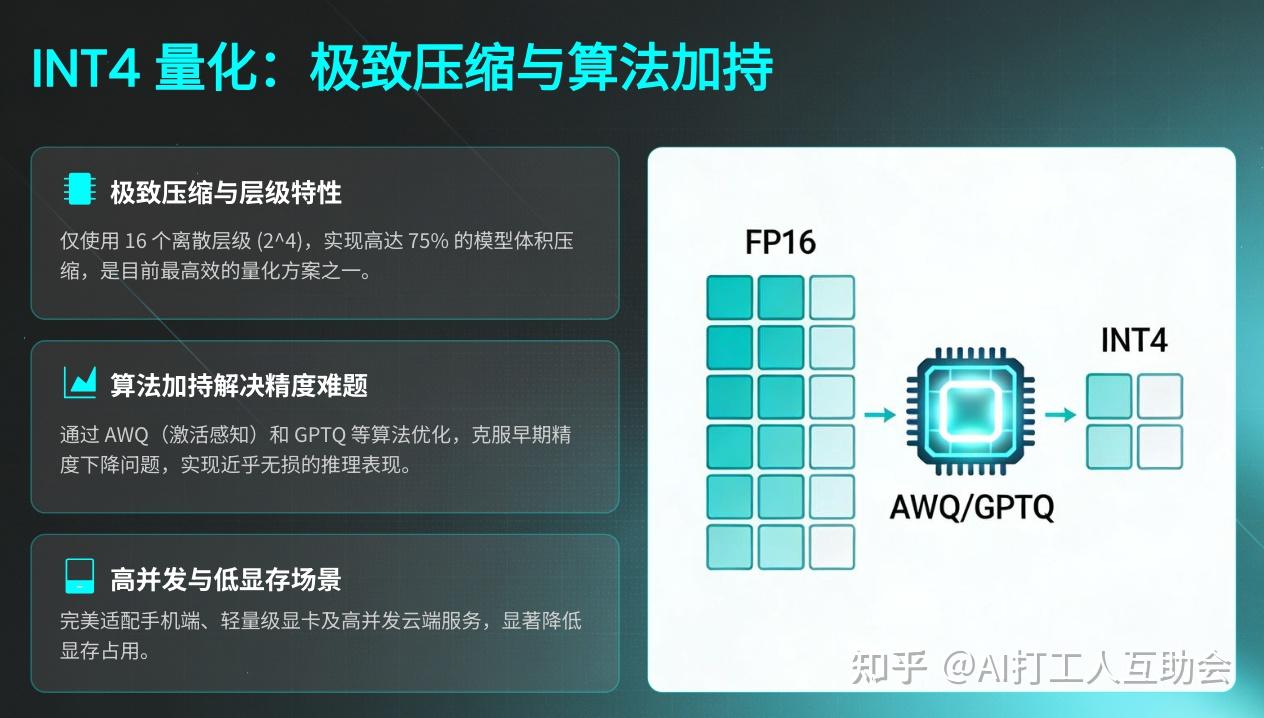






{kind=link}